
Improve Your Incident Response Process with Service Mapping
Introduction
Incident response is the structured process IT teams use to detect, contain, and resolve unplanned disruptions to services, systems, or infrastructure. Effective incident response depends on knowing how every component in your IT environment connects and what breaks when one of those components fails. Service mapping gives IT operations teams, infrastructure architects, and SREs the real-time dependency visibility they need to cut resolution times, reduce unplanned downtime, and build more resilient systems.
This article covers five ways service mapping strengthens your incident response process, from initial asset inventory through continuous security testing.
What Is Service Mapping and Why Does It Matter for Incident Response?
Service mapping in IT incident response is the automated process of discovering and visualizing the dependencies between IT components — servers, applications, databases, and network devices — so that when an incident occurs, responders can immediately identify which services are affected, trace the root cause, and determine the scope of impact. Organizations using service mapping report faster root cause isolation and lower MTTR compared to teams relying on manual dependency documentation.
Without service mapping, IT teams face blind spots: they lack a real-time view of interdependencies, which forces manual investigation, extends mean time to resolution (MTTR), and increases the risk of cascading failures. With service mapping in place, responders can trace the blast radius of any incident in seconds rather than hours.
5 Ways to Use Service Mapping to Improve Your Incident Response
1. Create an IT Asset Inventory and Conduct a Risk Assessment
A complete, accurate asset inventory is the foundation of any effective incident response plan. IT teams can use IT discovery technology to automatically identify every device on the network — physical hardware, virtual machines, cloud instances, and software — and compile that data into a structured inventory.
Service mapping layers on top of this inventory to visualize how assets relate to one another. Once the map is built, teams can run a risk assessment against it, examining data points such as software versions, open ports, and unpatched systems to identify vulnerabilities before they become incidents.
Continuous IT discovery supports incident response planning by keeping the asset inventory and service map current as the IT environment changes. When new devices, applications, or cloud resources are provisioned, automated discovery adds them to the CMDB and updates dependency relationships immediately. This ensures that incident response runbooks and risk assessments reflect the actual live environment, not a stale point-in-time snapshot that could lead responders to incorrect conclusions during an active incident.
Virima’s IT discovery capability scans hybrid environments agentlessly, feeds discovered assets directly into the CMDB, and surfaces dependency relationships that would otherwise require manual documentation.
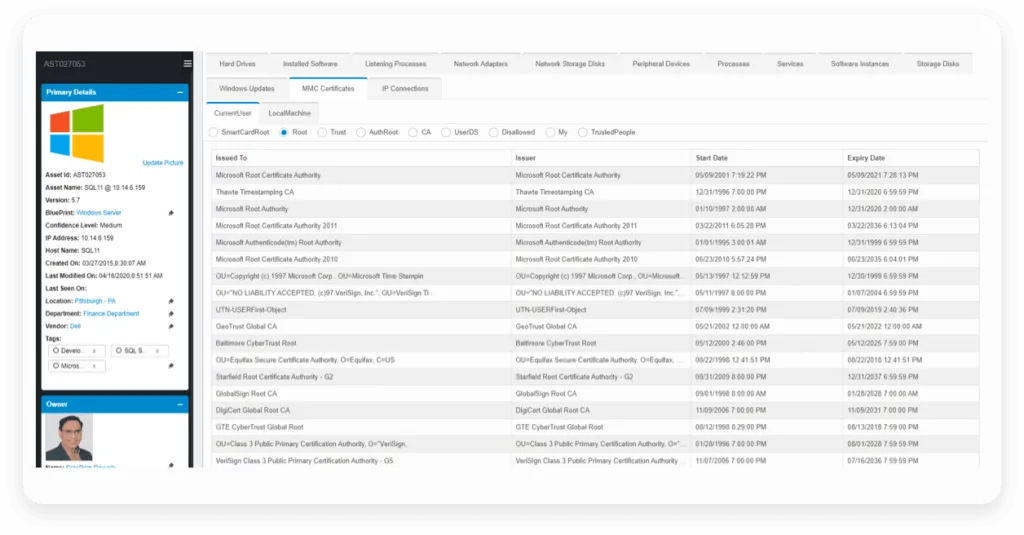
An example of an asset inventory available within Virima’s dashboard
2. Display Alerts in Real-Time and Resolve Incidents Faster
Real-time alerting is only as useful as the context that surrounds it. A bare alert telling responders that a server is down provides far less value than an alert overlaid on a service map showing which applications depend on that server, which business processes are affected, and which upstream or downstream components are at risk.
Service mapping technology enables IT teams to visualize the full landscape of their infrastructure at the moment an incident is triggered. This context allows teams to pinpoint the root cause more accurately and immediately assess the scope of impact, rather than spending the first hour of a response just figuring out what broke and why.
Teams that use service mapping for alert contextualization can distinguish between a symptomatic alert and the root cause alert faster, reducing unnecessary parallel investigation and focusing responders on the right problem from the start. It also accelerates stakeholder communication by making the affected service scope immediately visible, cutting the time between incident detection and coordinated response.
Service mapping also helps teams recognize incident patterns over time. When the same configuration or dependency repeatedly surfaces in incidents, teams can address the underlying structural issue rather than treating each event in isolation.
3. Reduce MTTR Through Increased Visibility Into Your Network
Mean time to resolution (MTTR) is one of the most tracked metrics in IT operations, and service mapping directly reduces it by eliminating the manual investigation phase of incident response. When a failure occurs, a dependency map allows responders to trace the failure path from symptom to root cause in real time, without correlating data across multiple disconnected tools. When responders can see, in real time, exactly how services are connected and where a failure has propagated, they can act immediately rather than investigating blindly.
According to research from EMA, organizations that maintain high CMDB accuracy — enabled by continuous discovery and service mapping — experience significantly shorter incident resolution cycles and fewer repeat incidents. Download the EMA Report on ServiceOps for supporting data on discovery maturity and operational outcomes.
Three ways service mapping reduces MTTR:
- Root cause isolation: A visual dependency map lets responders trace a failure path from the symptom back to its source without manual correlation across multiple tools.
- Stakeholder communication: When the affected service’s dependencies are visible, operations teams can communicate precisely with application owners, vendors, and business stakeholders without waiting for the investigation to complete.
- Post-incident documentation: Service maps generate accurate records of what was affected and in what sequence, improving runbooks and reducing resolution time for similar future incidents.
Virima’s ViVID Service Mapping displays open incidents and their impacted assets in a single interface, so responders always know what is affected without switching between tools.
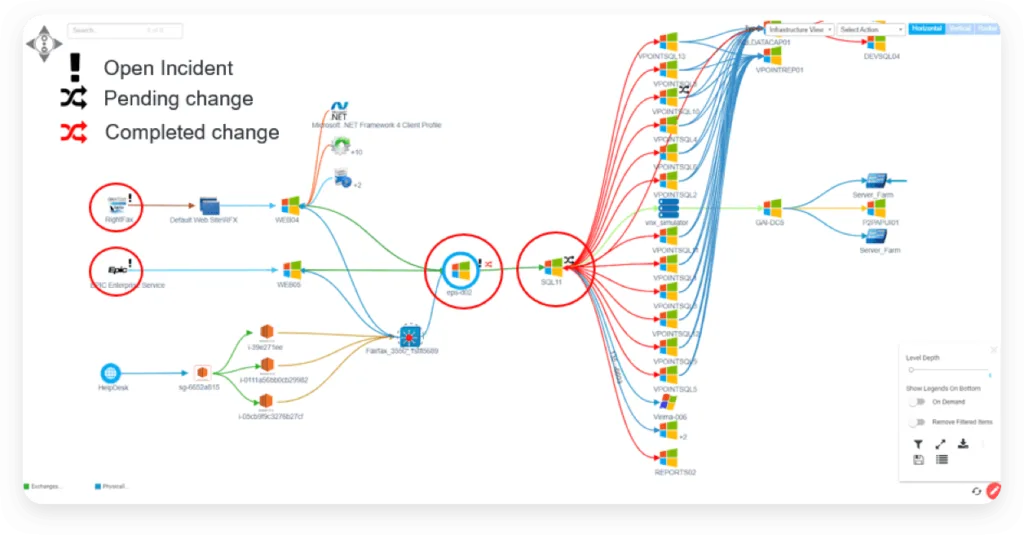
Virima allows you to view which incidents are open at any given point and which assets have been impacted
4. Create a Comprehensive Incident Response Plan with Robust Integrations
An incident response plan is only as effective as the data feeding into it and the tools executing it. Siloed ITSM platforms, disconnected monitoring tools, and manually maintained CMDBs create gaps that slow response when incidents escalate.
An effective service mapping tool for incident response should integrate with ITSM platforms such as ServiceNow, Jira Service Management, or Ivanti to create a unified workflow; cloud providers such as AWS and Azure for hybrid environment coverage; and security databases such as NIST for vulnerability correlation. These integrations allow real-time impact analysis, centralized incident management, and automated risk identification without requiring manual data entry or context switching between tools.
Virima integrates with leading service desk platforms and security databases to create exactly that kind of unified workflow. Current integrations include:
- Service desks: ServiceNow, Ivanti, Jira Service Management, Hornbill, Xurrent, HaloITSM
- Cloud platforms: AWS, Microsoft Azure
- Security databases: NIST, Tufin, and others
Virima connects to service desks without requiring an admin agent installation, which simplifies deployment in complex hybrid environments and supports compliance with industry standards. Its automated discovery process also allows administrators to pinpoint potential problems before they become major incidents, helping reduce MTTR and improve MTBF (Mean Time Between Failures).
For a full view of Virima’s integration ecosystem, visit the Integrations page.
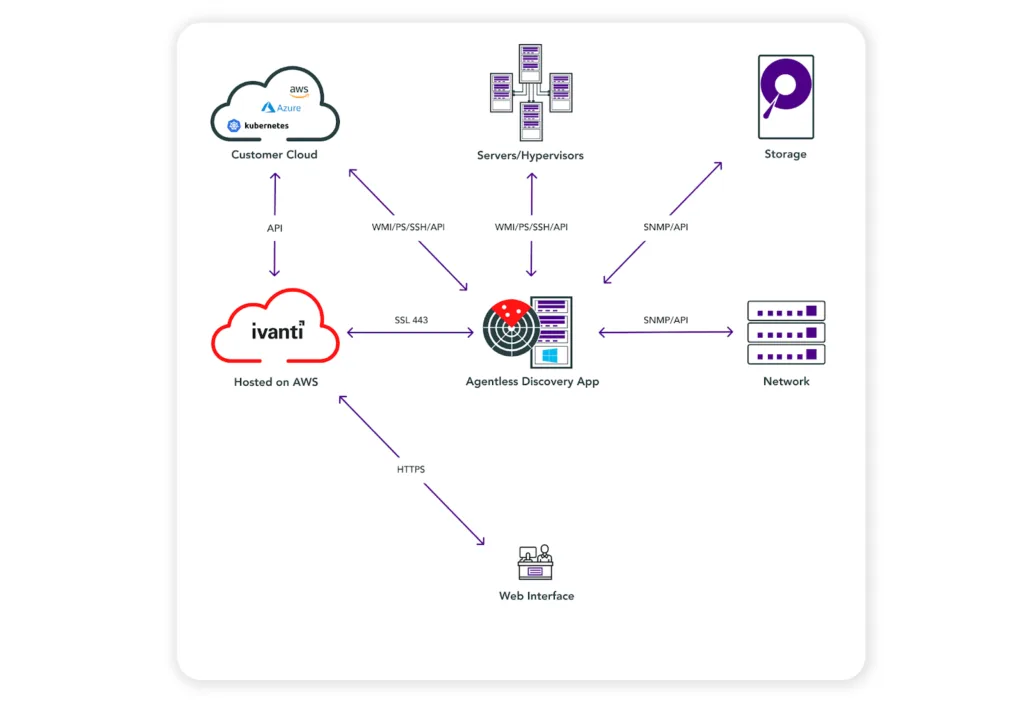
Here is how Virima integrates with popular service desk platforms like Ivanti
5. Test Your Security Posture More Often Through Automated Solutions
Security testing frequency matters because threat landscapes change continuously. According to the 2022 Core Security Pen Testing Report, 42% of cybersecurity professionals conduct penetration tests only once or twice a year, leaving gaps that attackers can exploit. Service mapping tools integrated with vulnerability databases enable continuous automated security assessment, allowing teams to correlate newly discovered vulnerabilities with specific services, prioritize remediation by business impact, and update incident response workflows before a threat is exploited.
This continuous testing capability allows IT teams to:
- Monitor the attack surface in real time as new assets and services are provisioned
- Correlate discovered vulnerabilities with specific services and their dependencies to prioritize remediation by business impact
- Create incident-specific response workflows for newly identified threat types using current vulnerability intelligence
Automating security assessment through service mapping also produces data that feeds directly into the incident response plan, ensuring response processes are built around the organization’s current threat profile rather than last year’s risk assessment.
For organizations managing disaster recovery alongside incident response, continuous security testing and service mapping together form the operational baseline for both proactive risk reduction and reactive recovery.
Improve Your Incident Response with Virima
Incident response performance depends on the quality of the information available to responders at the moment an incident occurs. Service mapping provides that information by maintaining a live, accurate, and dependency-aware view of the entire IT environment, from individual assets through the services that depend on them.
Virima’s ViVID Service Mapping, combined with agentless IT discovery and a purpose-built CMDB, gives IT operations teams, SREs, and infrastructure architects the operational context to resolve incidents faster, reduce repeat failures, and build more resilient services.
Frequently Asked Questions
What is the difference between IT discovery and service mapping?
IT discovery is the automated process of identifying all hardware, software, and cloud assets on a network. Service mapping builds on discovery by visualizing the relationships and dependencies between those assets. Discovery answers “what exists in my environment?” Service mapping answers “how does everything connect, and what breaks when one component fails?”
Can service mapping work in hybrid cloud environments?
Yes. Modern service mapping tools, including Virima, are designed to operate across hybrid environments spanning on-premises infrastructure, private data centers, and public cloud platforms such as AWS and Azure. Agentless discovery methods reduce deployment complexity and ensure coverage without requiring software installation on every managed device.
How does service mapping support change management alongside incident response?
Service mapping provides the dependency context needed to assess the risk of proposed changes before they are implemented. By showing which services and assets a change will affect, service mapping helps change managers avoid introducing incidents and supports faster rollback if a change causes unexpected failures. Learn more about change management with Virima.
What metrics improve when organizations implement service mapping?
Organizations that implement service mapping typically see improvements in MTTR (mean time to resolution), MTBF (mean time between failures), CMDB accuracy, and security posture assessment frequency. Virima customers also report reduced context switching during incident response, as integrated service desk and service mapping workflows consolidate the response process into a single platform.
Explore how Virima supports the full incident response and MTTR reduction use case, or book a demo to see the platform in action.





